12 important HTTP topics by Kenno
An attempt to grasp the fundamentals of how data is exchanged on the Web and the laws that govern it.

Building 👉 https://startupmaya.com
Kenno 🐛 wrote this article, and I'm only a middleman that publishes it under my name. Those who have read some of the previous posts of this account are well aware of who Kenno is and why I am publishing these...
1. What is HTTP ?
The Hypertext Transfer Protocol (HTTP) is an application layer protocol in the Internet protocol suite model for distributed, collaborative, hypermedia information systems. HTTP is the foundation of data communication for the World Wide Web. ~ Wikipedia
Hypertext was reviewed in the previous post, and we learnt that Hypertext Transfer Protocol (HTTP) is an Application/Process layer protocol in the article "8 important TCP/IP topics." So, in this article, we'll go over this protocol in further depth.
HTTP is primarily used to send and receive hypermedia documents such as HTML, and it is easy to extend and experiment with new functionalities.
The HTTP protocol follows the traditional client-server architecture, which is a distributed application structure that divides responsibilities or workloads between resource or service providers (web servers) and service requesters (clients/web browsers). Where a client establishes a connection in order to send a request, it then waits for a response.
HTTP is a stateless (not session-less) protocol, which means the server does not have to keep session state (data) from previous requests. The sender sends the receiver relevant session state (data) in such a way that each request can be understood independently.
2. History of HTTP
Sir Timothy John Berners-Lee, an English computer scientist at CERN, started the development of HTTP in 1989, and it was described in a brief text detailing the behavior of a client and a server using the initial HTTP protocol version, which was designated 0.9. It was created to allow web browsers and servers to communicate, but it can also be used for other purposes.
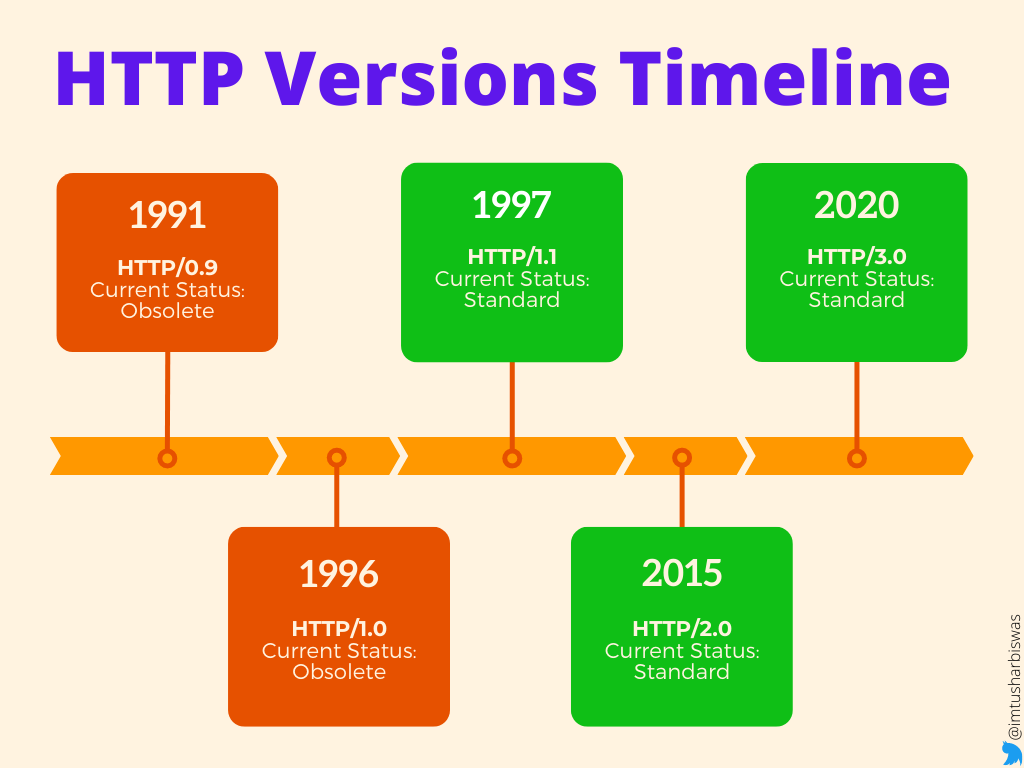
HTTP/0.9 quickly evolved into a more complex version, which was finished and fully described in 1996 as version 1.0.
In 1997, HTTP/1.0 was upgraded to version 1.1, and its specifications were modified in 1999 and 2014.
HTTP/2.0 was released in 2015 as a more efficient expression of HTTP's semantics "on the wire."
HTTP/3.0 is the intended successor to HTTP/2.0, and it is on the verge of becoming a standard.
3. HTTP Usage statistics
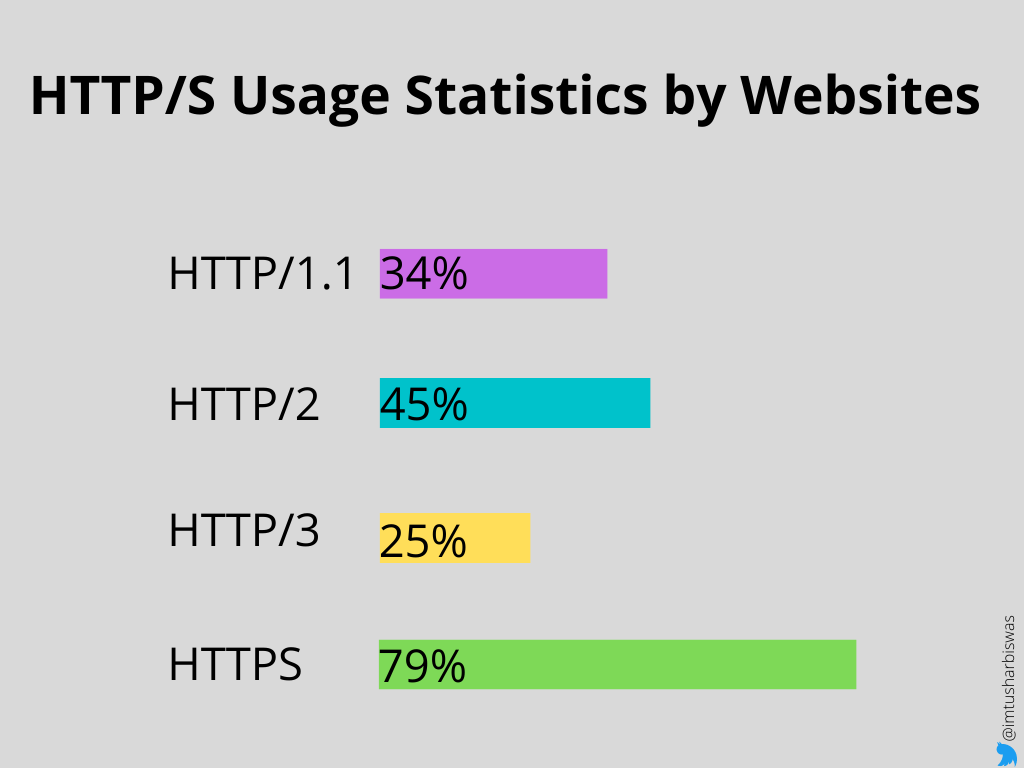
According to W3techs, HTTP/1.1 is used by roughly 34% of websites, HTTP/2 is used by approximately 45 percent of websites, HTTP/3 is used by approximately 25% of all websites, and HTTPS is used by approximately 79 percent of all websites.
4. Request For Comments
A Request for Comments (RFC) is a publication in a series, from the principal technical development and standards-setting bodies for the Internet, most prominently the Internet Engineering Task Force (IETF). ~Wikipedia
Steve Crocker created the RFC system in 1969 to keep track of unofficial notes about the progress of ARPANET. Unlike modern RFCs, many of the early RFCs were labeled as such to avoid seeming too declarative and to promote discussion. Various RFCs on networking protocols, method applications, and concepts have been produced since its inception.
The Internet Engineering Task Force (IETF), the Internet Research Task Force (IRTF), the Internet Architecture Board (IAB), and Independent Submissions all contribute to this official documentation, which includes technical and organizational documents about the Internet, specifications and policy documents.
- The first Request for Comments, RFC 1 Host Software was published in April 1969 and the latest one is RFC 9260 Stream Control Transmission Protocol published in June 2022.
Some of the HTTP RFC documents are:
RFC 1945 Hypertext Transfer Protocol HTTP/1.0 published in MAY 1996 (Status: INFORMATIONAL).
RFC 7230 Hypertext Transfer Protocol (HTTP/1.1): Message Syntax and Routing published in JUNE 2014 (Status: PROPOSED STANDARD).
RFC 7541 HPACK: Header Compression for HTTP/2 published in MAY 2015 (Status: PROPOSED STANDARD).
STD 99 RFC 9112 HTTP/1.1 published in JUNE 2022 (Status: INTERNET STANDARD) Obsoletes: RFC 7230.
- RFC 9113 HTTP/2 published in JUNE 2022 (Status: PROPOSED STANDARD).
We can read more about HTTP specifications here.
5. The Client, The Proxy and The Server
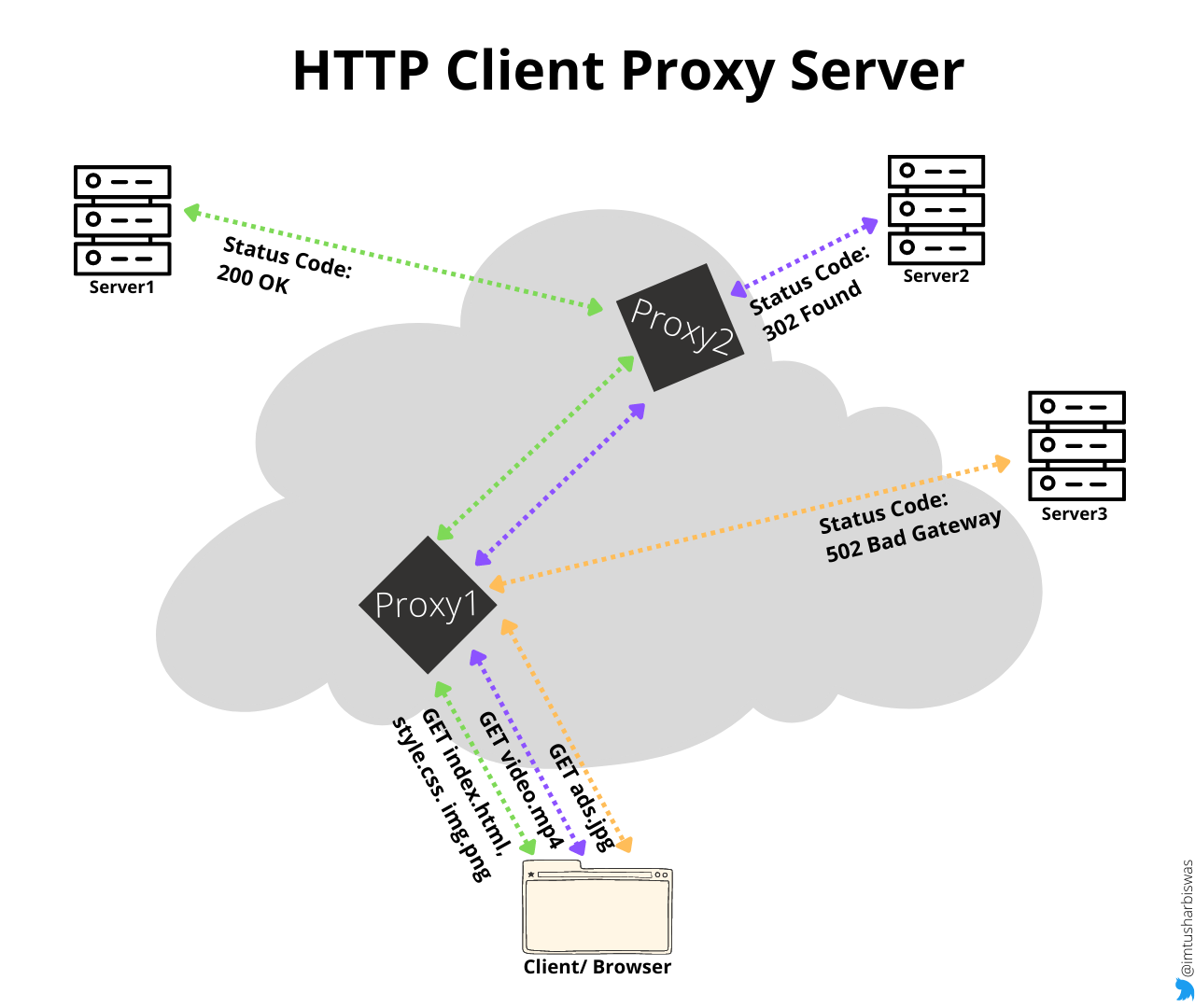
A client, also known as a user-agent, is any tool that acts on behalf of the user. Typically, our browser is the one that initiates the connection. The browser fetches and aggregates multiple resources from various locations to show a complete web page.
There are numerous entities between the client and the server, collectively known as proxies, that perform various operations such as caching (the cache can be public or private, like the browser cache), filtering (such as an antivirus scan or parental controls), load balancing (to allow multiple servers to serve different requests), authentication (to control access to different resources), and logging (allowing the storage of historical information)
The server's primary responsibility is to provide the resource requested by the client. Virtually, a server may appear to be a single machine, but it may actually be a number of servers sharing the load (load balancing). On the same system, many server software instances can be hosted.
6. HTTP Request Methods / Verbs

The request methods GET, POST, PUT, DELETE, and PATCH are more important to a web developer. A request method is considered safe if it does not make any changes (read-only) to the upstream server (a server that is located higher in a hierarchy of servers) a.k.a origin server. GET, HEAD, OPTIONS, and TRACE are safe methods, while rest is dangerous.
GET, POST, and DELETE are idempotent, which means that the result of a single request (GET/POST/DELETE data "x") and numerous identical requests using these methods will be the same.
Since responses to GET, POST & HEAD are allowed to be saved for future reuse, these methods are considered cacheable, even though the vast majority of cache implementations only support GET and HEAD.
All methods, except HEAD receive responses with a payload body.
For GET, HEAD, DELETE, CONNECT, OPTIONS METHODS sending requests with payload body is optional, for POST, PUT, PATCH its required and for TRACE its not required.
7. HTTP Response Status Codes
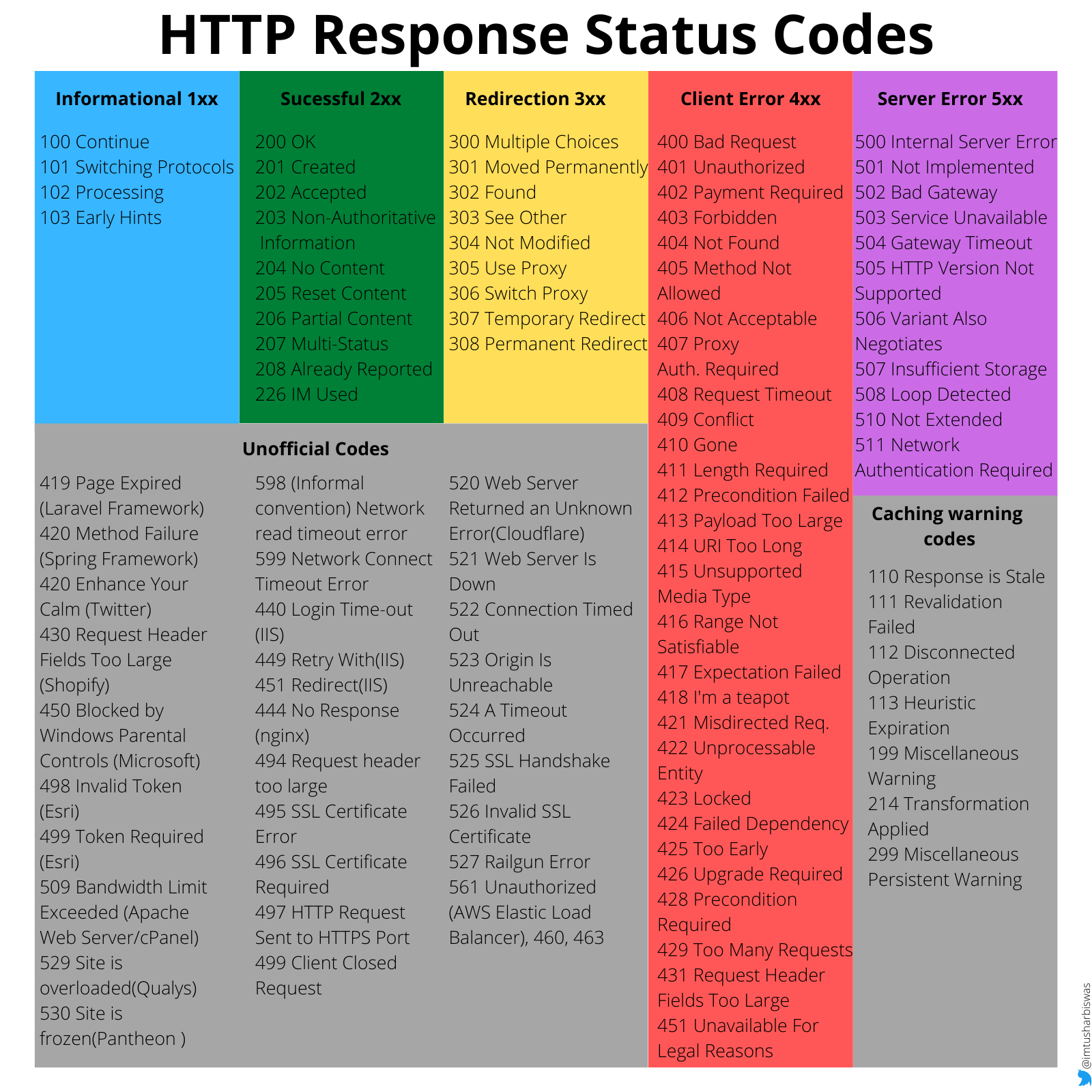
HTTP response status codes tell the client whether or not a particular HTTP request was completed successfully. The responses are mainly divided into five categories such as Informational responses (1xx), Successful responses (2xx), Redirection messages (3xx), Client error responses (4xx), Server error responses (5xx).
8. Request & Response
- When we type https://hashnode.com/search into the address bar of our browser and hit enter, we are actually telling the browser to send a GET request for a specific data / resource of the website.
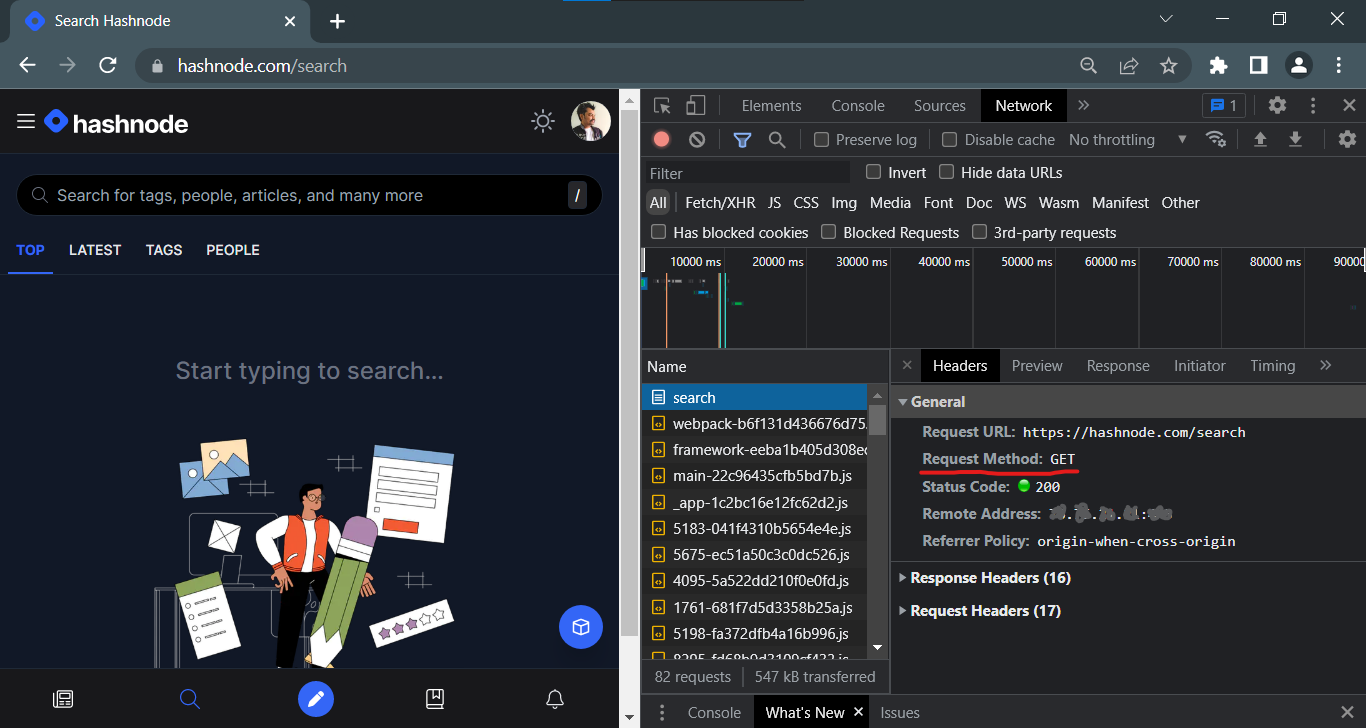
The user-agent (web browser/web crawler) or a proxy acting on its behalf then attempts to connect to the server.
Once a server is up and running, it starts listening on a specific port for incoming connection requests, accepts the connection, and waits for the client's request message.
The server responds with an HTTP response message after receiving the request (header plus a body if it is required). The requested resource is usually returned in the body of this message, although an error message or other information may also be returned.
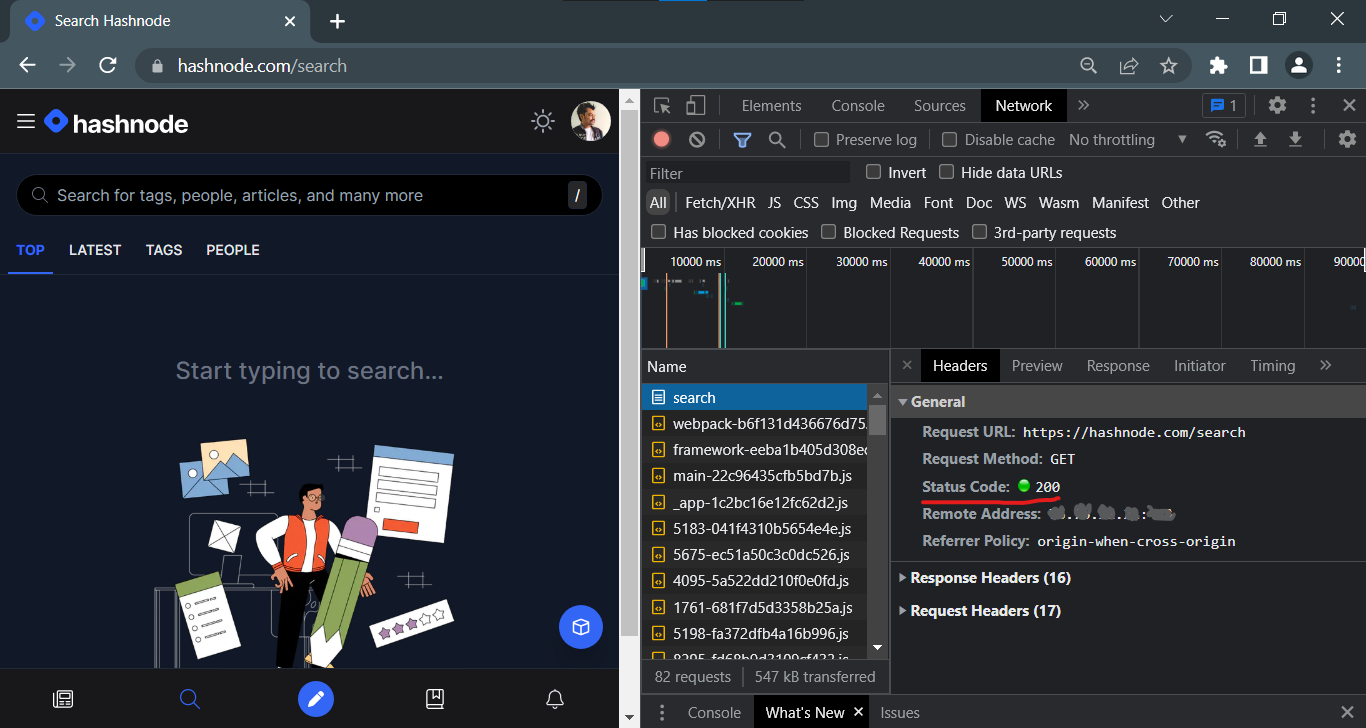
- For a variety of reasons the client or server can terminate the connection at any time. Closing a connection is commonly announced ahead of time by including one or more HTTP headers in the last request/response message delivered to the server or client.
9. HTTP Messages Format
HTTP requests and responses have a similar structure and are made up of the following elements:
A start-line detailing the requests to be implemented, as well as their success or failure status. This is always a single line to begin with.
An optional set of HTTP headers defining the body of the message or specifying the request.
All meta-information for the request has been sent, as indicated by a blank line beginning with carriage return and new line feed(\r \n).
An optional body containing data related to the request (such as the content of an HTML form) or the response page. The start-line and HTTP headers specify the presence of the body and its size.
Despite the fact that things appear to be different in the browser's developer tools, we can still see that a total of 86 requests have been made, along with the request method, status code, and protocol used for the specific communication. If you want, we can look into each request separately. We can even investigate further each request individually if we want.
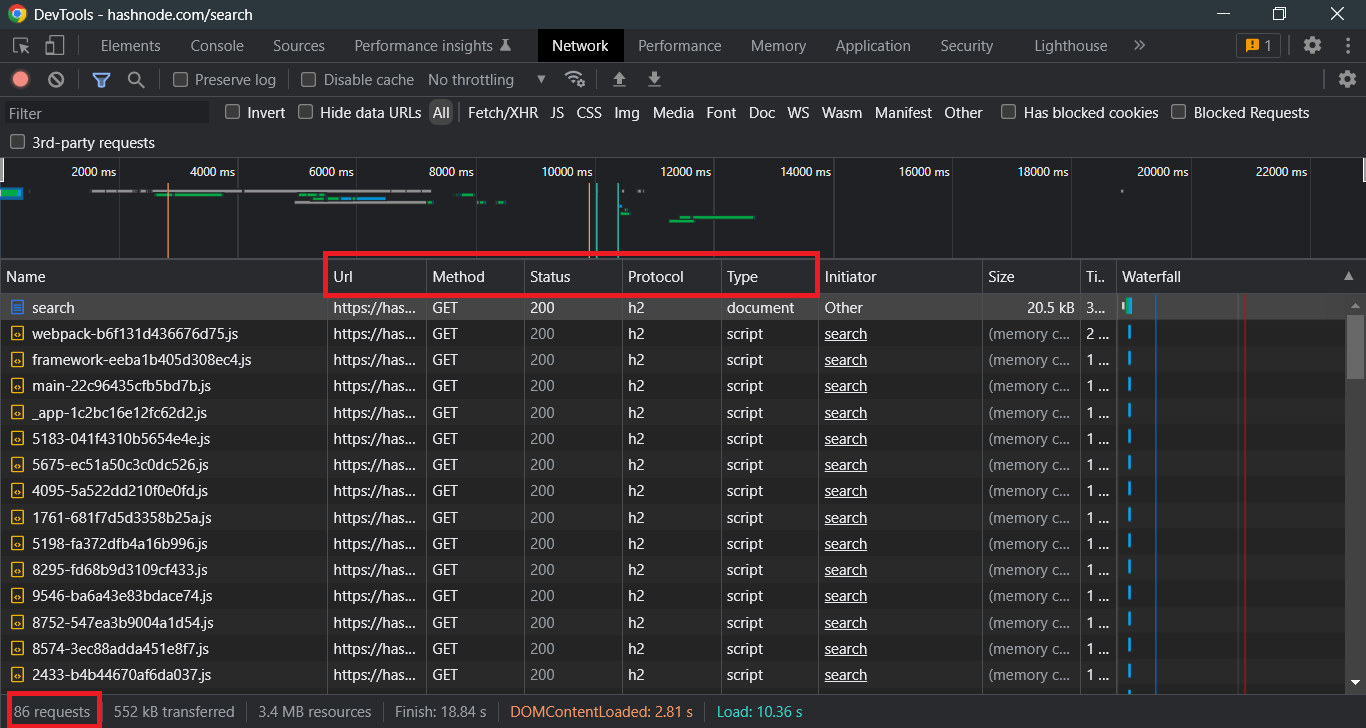
Request Headers:
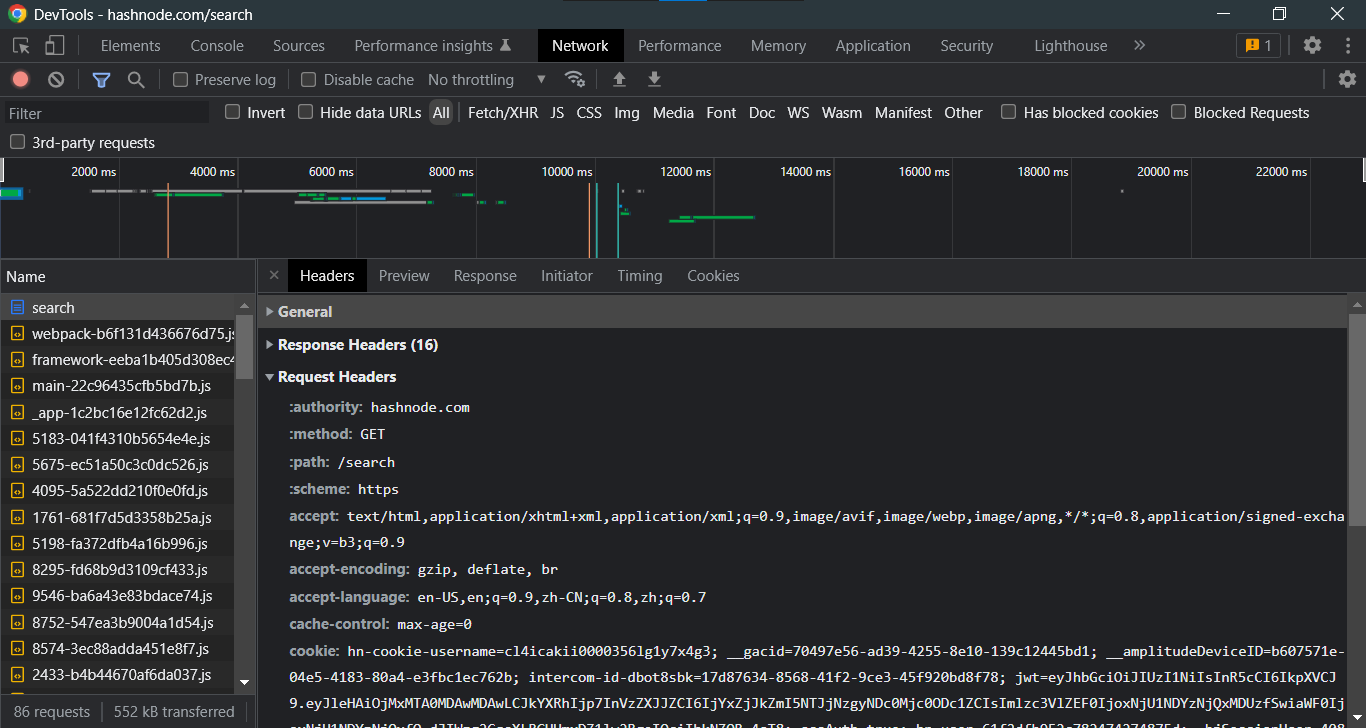
Response Headers:
We will not go over all of the lines in the request and response headers in this article, but a few lines such as method, path, scheme, content-type, and date are plainly apparent and self-explanatory.
10. HTTP Caching
The goal of caching in HTTP/1.1 is to eliminate the need to send requests in many cases, and to eliminate the need to send full responses in many other cases. ~ W3C
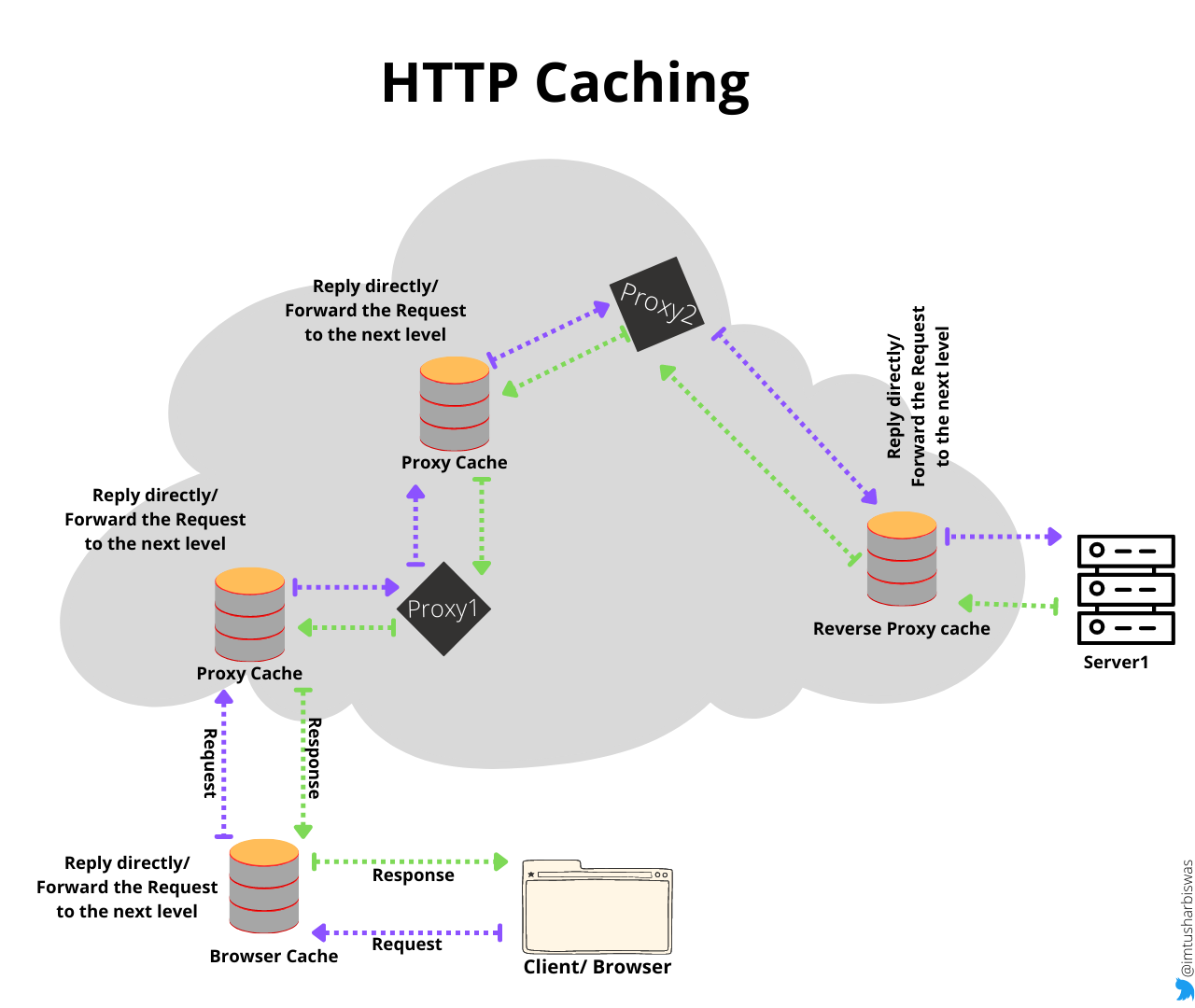
No one wants to visit a website that takes too long to load. HTTP caching is used to make web pages load faster. When a client requests a resource, the resource is first verified in the cache to see if it is available. If it is, the client is delivered the resource. If the requested resource is not in the cache, it will first be retrieved from the origin server, then the response will be cached (if cacheable) and the response will be given to the client. When the client requests the same resource again, the request will be provided by the cache rather than going all the way to the origin server.
As a result, some advantages of HTTP caching include faster responses, less traffic to the origin server, and reduced load when the response is processed by the cache.
Different types of caches are, Browser cache, Proxy Cache (located between the client and the server) , Reverse Proxy cache (close to the origin server).
11. HTTP Cookies
HTTP cookies (also called web cookies, Internet cookies, browser cookies, or simply cookies) are small blocks of data created by a web server while a user is browsing a website and placed on the user's computer or other device by the user's web browser. ~Wikipedia
Cookies are mostly used by websites to handle login sessions, shopping carts, gaming scores, user preferences, themes, and other settings, as well as to record and analyze user activity, track unique visitor count, and anything else the server needs to remember. Cookies can trace a user's activities, which can be beneficial or dangerous depending on the website.
12. HTTPs
Hypertext Transfer Protocol Secure (HTTPS) is an extension of the Hypertext Transfer Protocol (HTTP). It is used for secure communication over a computer network, and is widely used on the Internet. ~ Wikipedia
HTTPS was created by Netscape Communications in 1994 for its Netscape Navigator web browser. Initially, HTTPS was used in conjunction with the SSL protocol. HTTPS was formally established by RFC 2818 in May 2000, as SSL evolved into Transport Layer Security (TLS). Google revealed in February 2018 that after July 2018, its Chrome browser would designate HTTP sites as "Not Secure." This step was made to urge website owners to use HTTPS in order to make the Internet more secure.
HTTPS is not a separate protocol; it is encrypted with Transport Layer Security (TLS), which is the successor to the now-deprecated Secure Sockets Layer (SSL) (SSL). As a result, the protocol is sometimes known as HTTP over TLS or HTTP over SSL.
The following are some distinctions between HTTP and HTTPs:
HTTPS URLs starts with "https://" whereas HTTP URLs starts with "http://".
The default port for HTTP is 80, whereas the default port for HTTPS is 443.
HTTP is not encrypted and hence subject to attacks such as man-in-the-middle and eavesdropping, but HTTPS encrypts data exchanges using TLS (cryptographic protocol designed to offer communications security across a computer network.) or SSL (deprecated) Digital Certificates.
HTTP works at the Application Layer and HTTPS works at the Transport layer.
HTTP communication is in open text, but HTTPS communication is encrypted.
Hello there 👋 Thank you very much for taking the time to read this post🙏 Please feel free to share your ideas, recommendations, comments, questions and I'll forward them to "Kenno". Also, if you've written something or have a reference on the same subject, kindly share it with me and I'll do my best to read it. I'll catch up with you later🙂




![History of SaaS [1960s-2020s] Emergence, Evolution, and Impact](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fstock%2Funsplash%2FDuHKoV44prg%2Fupload%2F42c6382f71ecc519f04b83fe9f9c67e9.jpeg&w=3840&q=75)